🎓 Eğitimler 🗃️ Blog 📜 Komut Listesi 🎯 Test 🏷️ Etiketler 💖 Faydalı Kaynaklar 🐧 Hakkında 📮 Geri Bildirim
Linux Dersleri |
GNU/Linux için Türkçe içerik sağlamak üzere kurulmuş bir platformdur.
GNU/Linux için Türkçe içerik sağlamak üzere kurulmuş bir platformdur.

Regex(Regexp), “regular expressions” yani “düzenli ifadeler” kısaltmasından gelen bir tanımlama. Regex sayesinde spesifik olarak istediğimiz türdeki veriler ile eşleşme sağlayacak şablonlar tanımlayabiliyoruz. Böylelikle metinsel verileri filtrelememiz de mümkün oluyor.
Linux sisteminde Regex yaklaşımını, sed awk grep find gibi çeşitli filtreleme araçları üzerinden kullanabiliyoruz. Söz konusu Regex’in Linux üzerinde kullanımı olduğunda, temelde iki tür Regex çeşidi mevcut:
ℹ️ Not: Esasen regex çeşidi olarak PCRE (Perl-Compatible Regular Expressions) da Linux üzerinde çeşitli araçlar tarafından destekleniyor fakat biz bu yazımızda PCRE'yi görmezden geleceğiz. PCRE, Perl dilindeki düzenli ifadeleri temel alarak geliştirilen bir regex türüdür. Daha fazla detay için bu doğrultuda araştırma yapabilirsiniz.
Öncelikle tanımlarda geçen “POSIX” kavramına açıklık getirecek olursak; POSIX, “Unix için Taşınabilir İşletim Sistemi Arayüzü” ifadesinin kısaltmasından gelen bir standart. Unix benzeri işletim sistemleri için ortak bir arayüz ve davranış tanımlayan bir dizi standardı temsil ediyor. Bu oluşum sayesinde tüm sistemler ortak yaklaşımları takip edip standart ekosisteme dahil olabiliyor. Yani en özet haliyle POSIX, uymak isteyenler için ortak standartlar belirleyip yayınlayan bir oluşum. Linux sistemlerinin bileşenleri de çoğunlukla bu standarda uygun geliştiriliyor. Daha fazla bilgi için buraya göz atabilirsiniz.
İki çeşit olmasına karşın Linux sistemindeki pek çok araç genellikle yalnızca basit Regex(BRE) yaklaşımının bir kısmını destekliyor. Eğer tam olarak “POSIX Basic Regular Expression (BRE)” şeklinde internet üzerinde araştırma yapacak olursanız, basit Regex için tanımlı olan pek çok metakarakter olduğunu görebilirsiniz.
Metakarakterler, ilgili işlevi temsil eden özel karakterler verilen isim. Örneğin Regex için yıldız işareti, bir önceki karakterin sıfır veya daha fazla kez tekrarlanacağı belirten bir metakarakter. Regex çeşidine göre bu metakarakterin sayısı da değişiyor. Yeri geldiğinde bu karakterin üzerinde ayrıca duruyor olacağız.
Bu metakarakterler sayesinde çeşitli şablonlar oluşturabiliyoruz. Fakat araçların hızlı çalışabilmesi için kimi araçlar tüm basit Regex kurallarını kontrol etmekle vakit kaybetmek istemediği için basit Regex kurallarının da yalnızca belirli bir kısmını destekleyebiliyor. Dolayısıyla kullandığınız aracın hangi tür Regex’i desteklediği ve bu Regex’in de hangi kurallarını yani hangi metakarakterlerini tanıdığını ilgili aracın yardım sayfalarından kontrol etmeniz gerekebilir.
Bu durumun farkında olmanız önemli çünkü Linux sistemi kendi içerisinde pek çok farklı amaç için pek çok farklı aracı bulunduruyor. Araçlar da kendi işlevlerini yerine getirebilmek için çoğunlukla verimli olduğunu düşündükleri yaklaşımlar doğrultusunda geliştiriliyorlar. Bu sebeple Linux sisteminde kullanacağınız bir aracının Regex kurallarının hangilerini desteklediğini öğrenmenin en doğru yolu, kullandığınız aracın manual gibi yardım sayfalarına bakmaktan geçiyor. Aksi halde neden tüm Regex şablonlarının tüm araçlarda çalışmadığını anlamlandırmada sorun yaşamanız kaçınılmaz.
Basit ve genişletilmiş Regex arasındaki tek fark, ? + {} ve | karakterlerinin kullanımlarıdır.
Temel (BRE) sözdiziminde, bu karakterlerin önüne bir ters eğik çizgi (\) eklenmedikçe özel bir anlamı yoktur.
Genişletilmiş (ERE) sözdiziminde ise tersine çevrilir: bu karakterler, önlerinde ters eğik çizgi (\) olmadıkça özeldir.
Kullandığınız araca göre, basit veya genişletilmiş Regex karakterlerinin dikkate alınma durumlarını belirtmek için özel bir seçenek eklemeniz gerekebilir. Örneğin grep aracı varsayılan olarak basit Regex destekliyorken, genişletilmiş Regex’i dikkate alması için -E seçeneği ile bu durumu özellikle belirtmemiz gerekiyor.
Basit ile genişletilmiş Regex arasındaki farkı net biçimde görmek için örneğin önceki karakteri bir veya daha fazla kez temsil eden artı + işaretinin kullanımını ele alabiliriz.
Basit Regex:

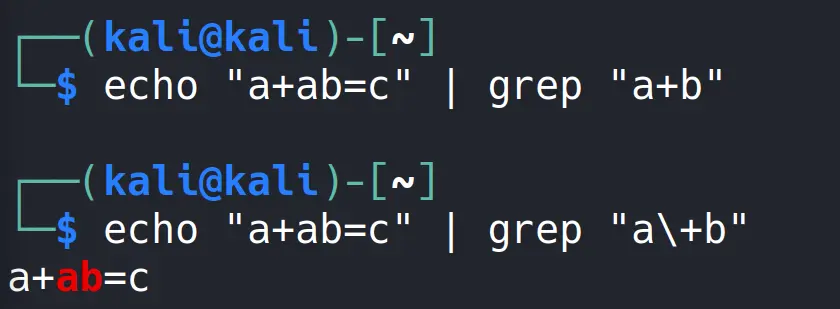
Bakın gördüğünüz gibi basit Regex üzerinde artı işareti tek başına bir anlam ifade etmediği için echo aracının çıktısındaki artı + işareti ile doğrudan eşleşme sağlayabildik. Basit genişletmede artı işaretinin özel anlamını kullanmak istediğimizde bu karakterden önce ters slash \ eklememiz gerek.

Bakın artı işaretinden önce kullandığım “a” karakterinin tekrarı olmadığı için hiç bir çıktı almadık çünkü basit Regex artı + işaretinin bu fonksiyonunu kullandığı için eşleşme de sağlanamadı.
Genişletilmiş Regex:
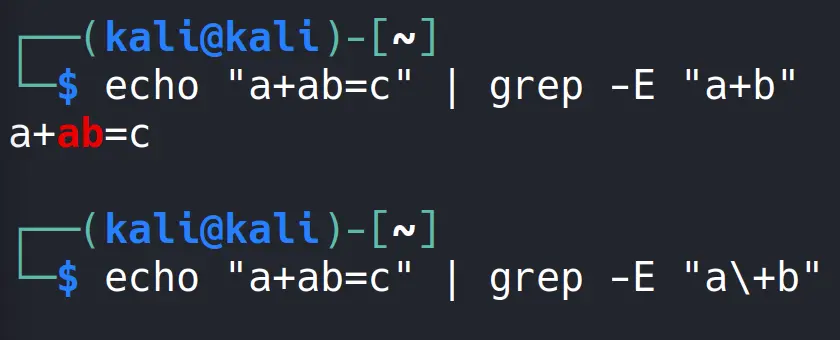
Şimdi genişletilmiş Regex üzerinde aynı işlemi denemek üzere -E seçeneğini de ekleyip komutumuzu girelim.

Bakın bu kez herhangi bir çıktı almadık, çünkü genişletilmiş genişletme kuralına göre artı işaretinden önceki karakterin tekrarı olması durumunda eşleşme sağlanacaktı. Yani “a” karakterinden hemen sonra yine “a” karakteri bulunsaydı çıktı alacaktık.
Şimdi bu genişletilmiş Regex kuralının bu özel artı + karakterini görmezden gelmesi için ters slash \ karakteri ile komutumuzu tekrar girelim.

Bakın artı işareti sıradan bir karakter olarak görüldüğü için eşleşme sağlandı ve çıktımızı aldık.
Basit ve genişletilmiş Regex arasındaki en temel işte budur. Basit Regex ters slash \ karakterini genişletmeleri uygulamak için kullanıyorken, genişletilmiş Regex ise tersi şekilde genişletmeleri görmezden gelmek için kullanıyor. Hatta kesin olarak teyit etmek için “aab=c” verisi üzerinde aynı işlemi tekrar edip, hangi genişletmenin ne zaman uygulandığına göz atabilirsiniz.
Basit Regex:
Genişletilmiş Regex:
Artı işareti kendisinden önceki karakterin tekrar edip etmediğini kontrol ettiği için sonuçlarımız yukarıdaki gibi oldu. Basit ve genişletilmiş
Hatırlatma: Regex üzerindeki bu farkın yalnızca '?' '+' '{}' ve '|' karakteri üzerinde geçerli olduğunu unutmayın. Diğer karakterler için bu fark geçerli değil.
*Bir önceki karakterin sıfır veya daha fazla kez tekrarlandığı desenleri temsil eder.

Bakın “a*” tanımı sayesinde “a” karakterinden sonra tekrar eden tüm “a” karakterleri desen eşleşmesine dahil oldu.
Eğer tam olarak “a*” karakterini filtrelemek istersem yıldız karakterinin görmezden gelinmesi için bu karakterden önce ters slash \ karakterini kullanabilirim.

Not: Basit genişletme üzerinde yalnızca ? + {} ve | karakterleri istisnadır. Bu karakterlerin özel anlamları dahilinde genişletmeleri için öncelerinde ters slash \ kullanmak gerekir.
.Yeni satır dahil herhangi bir karakterle eşleşir.

Eğer tam olarak “a.” karakterini filtrelemek istersem nokta karakterinin görmezden gelinmesi için bu karakterden önce ters slash \ karakterini kullanabilirim.

^Satırın başında bulunan desen eşleşmeleri içi kullanılır.
Örneğin “/etc/passwd” dosyasındaki satırlardan, başında “kali” ifadesi geçenleri filtrelemek için kullanabiliriz.

Gördüğünüz gibi yalnızca satırın başında bulunan “kali” ifadesi filtrelendi. Teyit etmek istersek şapka işareti olmadan tekrar girebiliriz.

Bakın satırın başından ziyade, hangi noktada geçtiği fark etmeksizin tüm “kali” ifadeleri filtrelenmiş.
Yani şapka işaretinin yalnızca satır başlarındaki desenler üzerinde geçerli olduğunu teyit etmiş olduk.
$Satırın sonunda bulunan desen eşleşmeleri içi kullanılır.
Örneğin “~/.bashrc” dosyasının sonunda geçen “user” ifadelerini filtrelemeyi deneyebiliriz.

Gördüğünüz gibi yalnızca satır sonunda geçen “user” ifadesi filtrelemiş olduk. Bu durumu teyit etmek için dolar işareti $ olamadan komutumuzu tekrar girebiliriz.

Bakın bu kez satır sonu yerine, herhangi bir konumda geçen tüm “user” ifadeleri filtrelenmiş oldu.
Yani dolar $ işaretinin satır sonundaki desenleri kapsadığını teyit etmiş olduk.
[liste]Listedeki tek bir karakter ile eşleşen desenler oluşturur.
Örneğin ben “a” “b” ve “c” karakterlerinden birini barındıranları filtrelemek için [abc] tanımını kullanıyorum.

Bakın gördüğünüz gibi yalnızca köşeli parantez içindeki karakterden biri barındıranlar filtrelenmiş oldu. Üstelik filtreleme işini daha spesifik hale getirmek için dilersek öncesinde veya sonrasında karakterler de ekleyebiliriz. Örneğin ben “c” ile başlayan ve devamında “a b c” karakterlerinden birini barındıranları filtrelemek istediğim için c[abc] tanımını kullanabilirim.

Eğer liste ile belirttiğimiz karakterler haricindekilerle eşleşme yapmak istiyorsak da listenin başına şapka işareti ^ ekleyebiliriz.
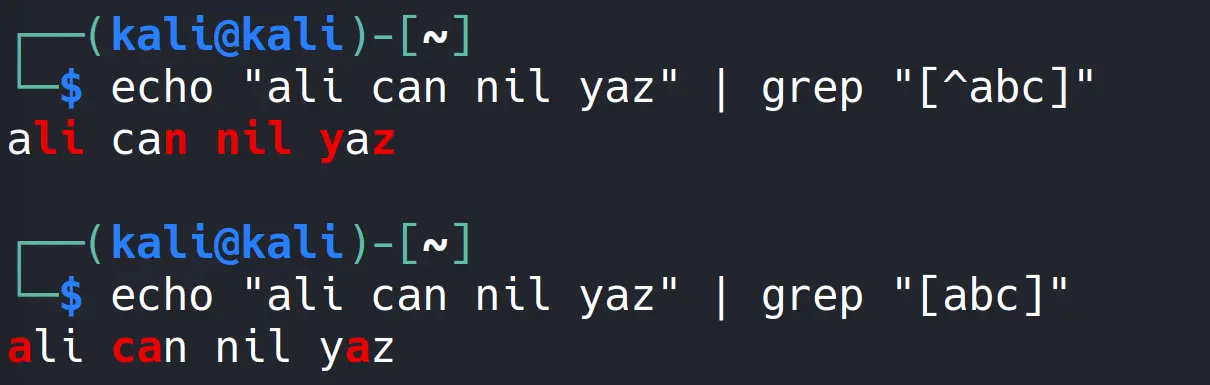
Bakın tam tersi şekilde köşeli parantez içindeki karakterin geçmediği desenler filtrelenmiş oldu.
Dilersek aralık belirtmemiz de mümkün. Ben örnek olması için küçük büyük harfler ile a’dan z’ye kadar olan karakterleri ve rakamları barındıran bir dosya ile çalışacağım.
┌──(kali@kali)-[~]
└─$ cat veri
a b c d e f g h i j k l m n o p q r s t u v w x y z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 0 1 2 3 4 5 6 7 8 9
Ben yalnızca a’dan k’ye kadar olanları filtrelemek istiyorum.

Bakın tam olarak benim belirttiğim gibi küçük harfli a’dan k’ye kadar olan karakterler filtrelenmiş oldu. Büyük harfleri ve sayıları da benzer şekilde ayrı ayrı filtreleyebiliriz.
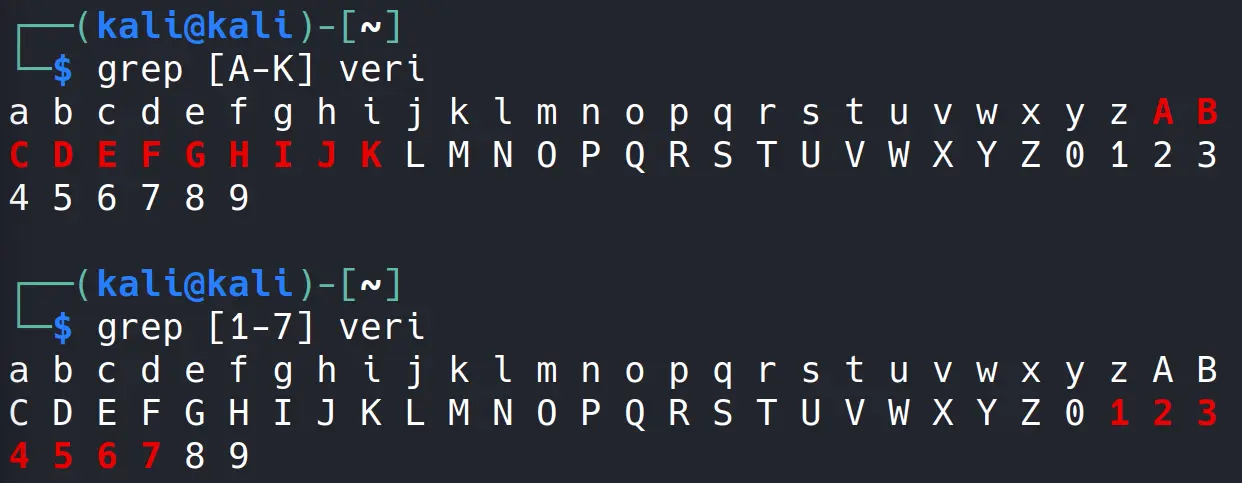
Dilersek hepsini tek seferde kapsamamız dahi mümkün.

Bakın a’dan k’ye kadar olan küçük büyük harfli karakterleri ve 1’den 7’ye kadar olan rakamları filtrelemiş olduk.
Köşeli parantez içinde kullanabileceğimiz belirli sınıfları sembolik olarak temsil eden çeşitli tanımlamalar mevcut. Bunları köşeli parantez içinde girmemiz gerekiyor.
[:alnum:]Yalnızca alfanümerik yani yalnızca harfler ve rakamlar dahilinde karakter desenleri için kullanılır.

Bakın yalnızca alfanümerik filtreleme yapılmış oldu.
Bu tanımlama aslında [A-Za-z0-9] tanımlaması ile aynı. Küçük büyük harfler ve 0’dan 9’a kadar olan tüm rakamları bu şekilde de ifade etmemiz mümkün.

[:alpha:]Küçük büyük harfler fark etmeksizin tüm alfabetik karakterler ile eşleşme sağlar.

Bu tanımlama [A-Za-z] ile aynıdır.

[:lower:]Yalnızca küçük harfli karakter desenleri ile eşleşme sağlar.

Bu tanımlama [a-z] ile aynıdır.

[:upper:]Yalnızca büyük harfli karakter desenleri ile eşleşme sağlar.

Bu tanımlama [A-Z] ile aynıdır.

[:digit:]Yalnızca rakam desenleri ile eşleşme sağlar.

Bu tanımlama [0-9] ile aynıdır.

[:blank:]space ve tab boşlukları ile eşleşme sağlar. Ben örnek için aşağıdaki dosyayı kullanacağım.
┌──(kali@kali)-[~]
└─$ cat veri2
bu ilk
bu ikinci
budasonsatır
Bakın ilk iki satırda space ve tab boşlukları var ama son satırında hiç boşluk yok. [:blank:] tanımı ile boşluk bulunanları filtrelemeyi deneyelim.
┌──(kali@kali)-[~]
└─$ cat veri2 | grep [[:blank:]]
bu ilk
bu ikinci
Bakın son satır getirilmedi çünkü son sarıda hiç boşluk bulunmuyordu.
[:punct:]Çeşitli (! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ \ ] ^ _ { |
} ~`) noktalama işaretlerini barındıran desenler ile eşleşme sağlar. |

Ben tüm hepsinden bahsetmedim, eğer tüm sınıfları öğrenmek isterseniz buraya göz atabilirsiniz.
\+Kendisinden önceki karakterin bir veya daha fazla kez tekrar ettiği desenler için kullanılır. Yıldız metakarakteri sıfır veya daha fazlasında geçerli iken, artı işareti bir veya daha fazlası için geçerli.
Ayrıca daha önce bahsettiğimiz gibi basit Regex üzerinde kullanmak için ters slash karakterinin de eklenmesi şart.
Örneğin ben “b” karakterinin bir kez veya daha fazla kez tekrar ettiği desenleri filtrelemek istiyorum.

Bakın tam olarak “b” karakterinin bir veya daha fazla gez geçtiği desenler filtrelenmiş oldu. Eğer artı işareti yerine yıldız kullanacak olsaydık, “b” karakterinin sıfır veya daha fazla kez geçtiği desenler filtrelenecekti.

Bakın “ac” ifadesinde “b” karakteri sıfır kez geçtiği için için yıldız karakteri bu ifadeyi de dahil etti. İşte artı ile yıldız karakteri arasındaki fark tam olarak bu örneklerde ele aldığımız durum.
\?Kendisinden önceki karakterin sıfır veya yalnızca 1 kez tekrar ettiği desenler oluşturur.
Denemek için “b” karakterinden sonra bu düzenli ifadeyi kullanabiliriz.

“ac” ifadesinde sıfır, “abc” ifadesinde ise yalnızca bir adet “b” karakteri bulunduğu için yalnızca bu iki ifade filtrelenmiş oldu. “b” karakterinin birden fazla kez tekrar ettiği desenler gördüğünüz gibi dahil edilmedi.
{sayı}Süslü parantezleri kullanarak bir karakterin üst üste tekrar sayısını belirtebiliyoruz.
Örneğin ben peşi sıra tam olarak 3 kez “a” karakterinin geçtiği desenleri filtrelemek istiyorum.

Bakın yalnızca tam olarak 3 kez üst üste tekrar eden “a” karakterleri filtrelenmiş oldu.
Tam sayı yerine aralık da belirtebiliriz. Bunun için sayıların arasına virgül koymamız yeterli. Ben 2 ile 4 arasında kez tekrar eden yani 2, 3 veya 4 kez üst üste tekrar edenleri filtrelemek istiyorum.

Bakın hem 2 hem 3 hem de 4 kez tekrar edenler filtrelenmiş oldu.
Ayrıca minimum veya daha fazla tekrar sayısını da belirtebiliriz. Bunun için minimum sayıdan sonra virgül koymamız yeterli. Ben örnek olması için minimum 3 kez tekrar edenleri filtreleyecek şekilde komutumu giriyorum.

Bakın minimum 3 yani 3, 4 ve 5 kez tekrar eden desenler filtrelenmiş oldu.
\|Yada koşulu belirtmek için kullanabiliyoruz. Örneğin “a” ya da “b” ifadelerini filtrelemek için kullanabiliriz.

Basit Regex ile genişletilmiş Regex arasındaki tek farkın ? + {} ve | karakterlerinin kullanımları olduğuna değinmiştik. Genişletilmiş Regex üzerinde bu karakterlerin özel anlamları ile ele alınması için bu karakterleri olduğu gibi yazmamız şart. Ve elbette genişletilmiş Regex kullanacağımız aracın genişletilmiş Regex’i desteklemesi gerekiyor. Kullandığınız aracın desteği olup olmadığını yardım sayfalarından veya kısa internet araştırması ile kolayca öğrenebilirsiniz.
Örneğin ben grep aracının desteğini sorgulamak için grep —help komutu ile yardım bilgisine göz atıyorum.
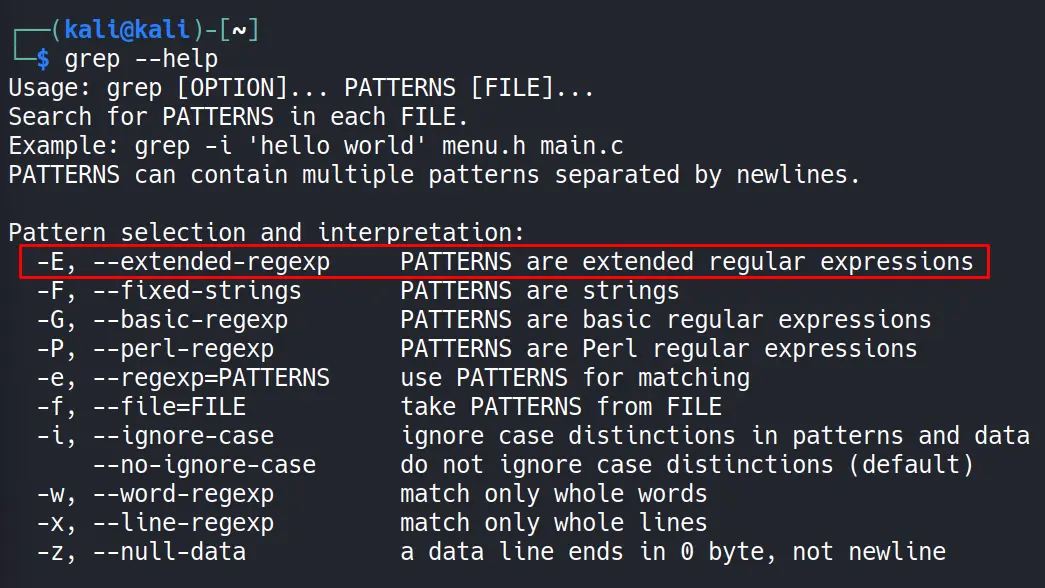
Bakın genişletilmiş Regex için -E seçeneğini veya —extended-Regexp seçeneğini özellikle kullanmamız gerektiği burada belirtiliyor.
Ben de genişletilmiş Regex’ten faydalanmak üzere grep aracıma -E seçeneğini verip komutumu öyle giriyorum.
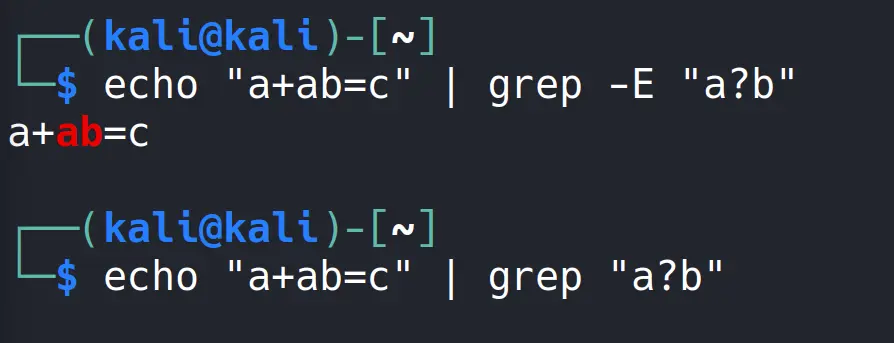
Görebildiğiniz gibi -E seçeneği yokken genişletilmiş Regex kuralları tanınmıyor. İşte benzer durum sistem üzerinde kullanacağınız herhangi bir araç için de aynen geçerli. Desteğini kontrol edin ve nasıl kullanabileceğinizi öğrenip komutunuzu uygun şekilde girin.
Regex konusu gerçekten çok detaylı bir konu, ben yalnızca Linux özelinde sık ihtiyaç duyabileceğimiz ve farkında olmamız gereken bazı kavramları ele aldım. Eğer daha fazla detay öğrenmek isterseniz buradan sed aracının GNU dokümantasyonuna göz atarak başlayabilirsiniz.
